
在数据驱动的现代开发中,高效处理 PDF 文档已成为 Java 开发者不可或缺的核心能力。无论是处理各类发票扫描件、业务分析报告,还是包含丰富图表的技术文档,掌握 Java 版的 PDF 解析技术都将大幅提升数据处理效率,充分释放文档中的商业价值。
E-iceblue旗下Spire系列产品,是文档处理组件领域的佼佼者,支持国产化信创。本指南将介绍如何使用 Spire.PDF for Java 读取 PDF 文档 ,涵盖从可搜索的 PDF 提取文本 、表格和 图片 ,以及通过 OCR 技术从扫描版 PDF 中读取文本。
用于读取 PDF 内容的 Java 库
选择适合的库是成功读取 PDF 的关键。Spire.PDF 以其稳定性和丰富功能脱颖而出,支持文本提取、图片获取、表格解析及 OCR 集成,其直观 API 和完善的教程对新手和专家同样友好。
开始前请从官网下载 Spire.PDF for Java 并添加至项目依赖。Maven 用户请在 pom.xml 中添加:
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.cn/repository/maven-public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>11.6.2</version>
</dependency>
</dependencies>
下文将演示如何运用 Spire.PDF 完成各类 PDF 读取任务。
Java 从可搜索 PDF 读取文本
可搜索 PDF 以机器可读的格式存储文本,便于高效提取内容。Spire.PDF 中的 PdfTextExtractor 类可直接获取可搜索PDF的页面文本,而 PdfTextExtractOptions 能灵活设置提取参数,包括文本布局处理策略和指定提取区域。
以下示例展示如何使用 Java 提取 PDF 所有页面的文本并输出到TXT文件:
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import com.spire.pdf.texts.PdfTextExtractOptions;
import com.spire.pdf.texts.PdfTextExtractor;
import com.spire.pdf.texts.PdfTextStrategy;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
public class ExtractTextFromSearchablePdf {
public static void main(String[] args) throws IOException {
// 创建一个 PdfDocument 对象
PdfDocument doc = new PdfDocument();
// 加载 PDF 文件
doc.loadFromFile("C:\\Users\\Administrator\\Desktop\\Input.pdf");
// 遍历所有页面
for (int i = 0; i < doc.getPages().getCount(); i++) {
// 获取当前页面
PdfPageBase page = doc.getPages().get(i);
// 创建一个 PdfTextExtractor 对象
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
// 创建一个 PdfTextExtractOptions 对象
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
// 指定提取策略
extractOptions.setStrategy(PdfTextStrategy.None);
// 从页面中提取文本
String text = textExtractor.extract(extractOptions);
// 定义输出文件路径
Path outputPath = Paths.get("output/Extracted_Page_" + (i + 1) + ".txt");
// 写入 txt 文件
Files.write(outputPath, text.getBytes());
}
// 关闭文档
doc.close();
}
}
效果图:

Java 从 PDF 文档读取图片
对于包含图形的 PDF,PdfImageHelper 类能精准提取所有嵌入式图片。通过 PdfImageInfo 对象可将图片保存为标准图像文件,特别适用于产品图册等视觉内容重要的文档。
以下Java示例将 PDF 文档中的所有图片提取为 PNG 文件:
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import com.spire.pdf.utilities.PdfImageHelper;
import com.spire.pdf.utilities.PdfImageInfo;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
public class ExtractAllImages {
public static void main(String[] args) throws IOException {
// 创建一个 PdfDocument 对象
PdfDocument doc = new PdfDocument();
// 加载 PDF 文档
doc.loadFromFile("C:\\Users\\Administrator\\Desktop\\Input.pdf");
// 创建一个 PdfImageHelper 对象
PdfImageHelper imageHelper = new PdfImageHelper();
// 声明一个整型变量
int m = 0;
// 遍历页面
for (int i = 0; i < doc.getPages().getCount(); i++) {
// 获取特定页面
PdfPageBase page = doc.getPages().get(i);
// 获取页面中的所有图像信息
PdfImageInfo[] imageInfos = imageHelper.getImagesInfo(page);
// 遍历图像信息
for (int j = 0; j < imageInfos.length; j++)
{
// 获取特定图像信息
PdfImageInfo imageInfo = imageInfos[j];
// 获取图像
BufferedImage image = imageInfo.getImage();
File file = new File(String.format("output/Image-%d.png",m));
m++;
// 以 PNG 格式保存图像文件
ImageIO.write(image, "PNG", file);
}
}
// 清理资源
doc.dispose();
}
}
效果图:

Java 从 PDF 文件读取表格数据
Spire.PDF 提供的 PdfTableExtractor 类能智能识别表格边界,生成的 PdfTable 对象保持原始结构,并支持使用 PdfTable.getText() 方法获取具体单元格中的文本。该功能特别适用于从财务报表等结构化文档提取数据。
以下 Java 代码将 PDF 中的每一个表格导出为单独的TXT文件:
import com.spire.pdf.PdfDocument;
import com.spire.pdf.utilities.PdfTable;
import com.spire.pdf.utilities.PdfTableExtractor;
import java.io.FileWriter;
public class ExtractTableData {
public static void main(String[] args) throws Exception {
// 创建一个 PdfDocument 对象
PdfDocument doc = new PdfDocument();
// 加载 PDF 文档
doc.loadFromFile("C:\\Users\\Administrator\\Desktop\\Input.pdf");
// 创建一个 PdfTableExtractor 实例
PdfTableExtractor extractor = new PdfTableExtractor(doc);
// 初始化表计数器
int tableCounter = 1;
// 遍历 PDF 中的页面
for (int pageIndex = 0; pageIndex < doc.getPages().getCount(); pageIndex++) {
// 从当前页面提取表格到 PdfTable 数组
PdfTable[] tableLists = extractor.extractTable(pageIndex);
// 如果找到任何表格
if (tableLists != null && tableLists.length > 0) {
// 遍历数组中的表格
for (PdfTable table : tableLists) {
// 为当前表格创建一个 StringBuilder
StringBuilder builder = new StringBuilder();
// 遍历当前表格中的行
for (int i = 0; i < table.getRowCount(); i++) {
// 遍历当前表格中的列
for (int j = 0; j < table.getColumnCount(); j++) {
// 从当前表格单元格中提取数据并附加到 StringBuilder
String text = table.getText(i, j);
builder.append(text).append(" | ");
}
builder.append("\r\n");
}
// 为每个表格写入一个单独的 .txt 文档
FileWriter fw = new FileWriter("output/Table_" + tableCounter + ".txt");
fw.write(builder.toString());
fw.flush();
fw.close();
// 增加表计数器
tableCounter++;
}
}
}
// 清理资源
doc.dispose();
}
}
效果图:

通过 OCR 将扫描版 PDF 转为文本
从扫描版的 PDF 提取文本需要依赖 OCR 引擎,如Spire.OCR for Java。本解决方案首先使用 Spire.PDF 的渲染引擎将页面转换为图片,然后通过 Spire.OCR 的 OcrScanner 类从图片识别文字。通过这两步法,可以有效地将实体文档扫描转换为可编辑文本,且支持多种语言。
步骤 1. 安装Spire.OCR 并配置环境
OcrScanner scanner = new OcrScanner();
configureOptions.setModelPath("D:\\win-x64"); // 模型路径
步骤 2. 将扫描的 PDF 转换为文本
此代码示例将扫描 PDF 的每一页转换为图像文件,应用 OCR 提取文本,并将结果保存到文本文件中。
import com.spire.ocr.OcrException;
import com.spire.ocr.OcrScanner;
import com.spire.ocr.ConfigureOptions;
import com.spire.pdf.PdfDocument;
import com.spire.pdf.graphics.PdfImageType;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
public class ExtractTextFromScannedPdf {
public static void main(String[] args) throws IOException, OcrException {
// 创建 OcrScanner 类的实例
OcrScanner scanner = new OcrScanner();
// 配置扫描器
ConfigureOptions configureOptions = new ConfigureOptions();
configureOptions.setModelPath("D:\\win-x64"); // 设置模型路径
configureOptions.setLanguage("Chinese"); // 设置语言
// 应用配置选项
scanner.ConfigureDependencies(configureOptions);
// 加载 PDF 文档
PdfDocument doc = new PdfDocument();
doc.loadFromFile("C:\\Users\\Administrator\\Desktop\\Input.pdf");
// 准备临时目录
String tempDirPath = "temp";
new File(tempDirPath).mkdirs(); // 创建临时目录
StringBuilder allText = new StringBuilder();
// 遍历所有页面
for (int i = 0; i < doc.getPages().getCount(); i++) {
// 将页面转换为图像
BufferedImage bufferedImage = doc.saveAsImage(i, PdfImageType.Bitmap);
String imagePath = tempDirPath + File.separator + String.format("page_%d.png", i);
ImageIO.write(bufferedImage, "PNG", new File(imagePath));
// 执行 OCR
scanner.scan(imagePath);
String pageText = scanner.getText().toString();
allText.append(String.format("\n--- PAGE %d ---\n%s\n", i + 1, pageText));
// 清理临时图像
new File(imagePath).delete();
}
// 将所有提取的文本保存到文件
Path outputTxtPath = Paths.get("output", "extracted_text.txt");
Files.write(outputTxtPath, allText.toString().getBytes());
// 关闭文档
doc.close();
System.out.println("文本已提取到 " + outputTxtPath);
}
}
效果图:

结语
在数字化转型的浪潮中,PDF 文档作为企业信息的重要载体,其高效处理能力已成为现代开发者的核心竞争力。通过本指南介绍的 Spire.PDF for Java 技术方案,开发者可以轻松应对各类 PDF 数据提取需求,从简单的文本和图片提取 到复杂的 表格数据解析 ,再到 扫描文档的智能识别 ,帮助企业更好地管理和利用文档信息。
此外,Spire.PDF for Java 提供了一套全面的工具和功能,使开发者能够构建起完整的文档自动化处理能力。无论是自动化生成报告、批量处理文档,还是提取特定数据以供分析,开发者都能通过灵活的 API 和丰富的示例代码,快速实现这些功能。这不仅提高了工作效率,也减少了人工操作的错误率,为企业带来了更高的生产力和竞争优势。
常见问题
Q1:如何使用 Java 从扫描 PDF 提取文本?
结合 Spire.PDF for Java 和 Spire.OCR for Java 即可实现:先将 PDF 页面转为图片,再进行 OCR 识别。
Q2:在Java 中读取 PDF 的最佳库是什么?
强烈推荐 Spire.PDF for Java,因为它功能多样且易于使用。它支持文本、图像、表格的提取以及 OCR 集成。
Q3:Spire.PDF 是否支持提取元数据、附件和超链接?
是的, Spire.PDF支持提取:
-
元数据(标题/作者/关键词)
-
附件(嵌入文件)
-
超链接( URL 和文档链接)
该库提供 PdfDocumentInformation 类获取元数据,以及用于获取附件( PdfAttachmentCollection )和超链接( PdfUriAnnotation )的方法。
Q4:如何以编程方式将 PDF表格提取为 CSV/Excel?
使用 Spire.PDF for Java,您可以从 PDF 中提取表格数据,然后通过 Spire.XLS for Java 无缝导出到 Excel(XLSX)或 CSV 格式。
————————————————————————————————————————
关于慧都科技:
慧都科技是一家行业数字化解决方案公司,长期专注于软件、油气与制造行业。公司基于深入的业务理解与管理洞察,以系统化的业务建模驱动技术落地,帮助企业实现智能化运营与长期竞争优势。在软件工程领域,我们提供开发控件、研发管理、代码开发、部署运维等软件开发全链路所需的产品,提供正版授权采购、技术选型、个性化维保等服务,帮助客户实现技术合规、降本增效与风险可控。慧都科技E-iceblue的官方授权代理商,提供E-iceblue系列产品免费试用,咨询,正版销售等于一体的专业化服务。E-iceblue旗下Spire系列产品是国产文档处理领域的优秀产品,支持国产化信创,帮助企业高效构建文档处理的应用程序。
欢迎下载|体验更多E-iceblue产品
获取更多信息请咨询慧都在线客服 ;技术交流Q群(125237868)
标签:
本站文章除注明转载外,均为本站原创或翻译。欢迎任何形式的转载,但请务必注明出处、不得修改原文相关链接,如果存在内容上的异议请邮件反馈至chenjj@evget.com
文章转载自:慧都网


 首页
首页 










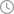
 7次
7次
 相关产品
相关产品 最新文章
最新文章 
 相关文章
相关文章 

 微信
微信 在线咨询
在线咨询




 渝公网安备
50010702500608号
渝公网安备
50010702500608号

 客服热线
客服热线